
AI/ML
 Chand Prakash
29 May 2026
Chand Prakash
29 May 2026
Custom AI Software Development: Complete Guide to Building Intelligent Solutions
 Chand Prakash
Chand Prakash

Imagine a world where AI understands you not just through your words, but through your expressions, the tone of voice, and even the flicker in your eyes. This isn’t science fiction, it’s the dawn of Multi-Modal AI, a revolutionary approach to artificial intelligence that’s rewriting the rules of human-computer interaction.
In a nutshell, Multi-Modal AI breaks free from the confines of text-based data. It’s like giving AI superpowers that enable it to process and understand multiple forms of information simultaneously. This blog explores everything we need to know about Multi-Modal AI Systems. Let’s start with what is Multi-Modal AI System and how it works.
Multi-modal AI systems are a new generation of artificial intelligence that can process and understand information from multiple sources, such as text, images, sound, and even touch. This is a significant departure from traditional AI, which is primarily focused on text and numerical data.
By combining different modalities, multi-modal AI systems can create a more comprehensive and nuanced understanding of the world around them. This allows them to perform tasks that are beyond the reach of traditional AI, such as:
In a race to revolutionize AI, OpenAI and Google are neck-and-neck in the development of groundbreaking multimodal systems that can seamlessly understand and generate text and images.
OpenAI has boosted its GPT models, allowing them to see and speak, creating more engaging user experiences. They’re also building “Gobi,” a new multimodal AI system from the ground up, separate from the GPT family.
Google’s multimodal large language model Gemini is another major player in this field. It’s extensive collection of images and videos from its search engine and YouTube has given it a significant advantage in the multimodal domain, placing considerable pressure on other AI systems to quickly enhance their multimodal capabilities.
A Multi-Modal AI System is a machine learning system that combines two or more models to improve their performance. This approach is often used to enhance the accuracy and reliability of AI systems in various applications, such as fraud detection, risk assessment, and image recognition.
The main idea behind multi-modal models is that each modality (e.g., text, image, video) provides unique information about the input data, and by combining multiple modalities, the model can capture more comprehensive and nuanced features. This is particularly useful in complex tasks, where relying on a single modality may not be sufficient to capture all relevant information.
Multimodal AI systems are fascinating, and their workings involve some intricate but interesting processes. Here’s a breakdown of how modules work.
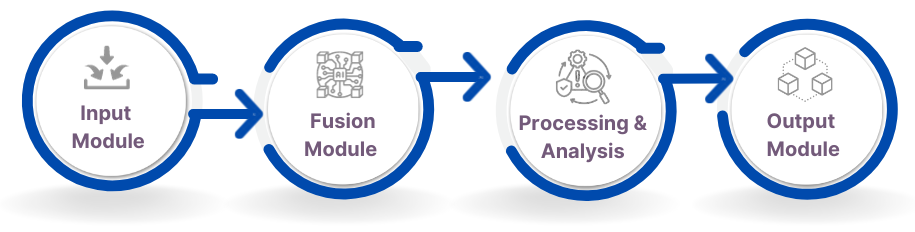
This stage gathers data from various modalities, like text from documents or conversations, images from cameras, audio from recordings, and video from sensors. Each modality’s data may go through pre-processing steps like normalization, cleaning, and feature extraction to prepare it for the next stage.
This is the heart of a Multi-Modal AI system, where information from different modalities is combined and analyzed for better understanding. Various fusion techniques exist.
The chosen technique depends on the specific task and data types involved.
The fused information is then processed by the AI model, which could involve deep learning algorithms like convolutional neural networks (CNNs) for images, recurrent neural networks (RNNs) for text, and specialized models for audio and video. The model analyzes the combined data, extracting patterns, relationships, and insights that wouldn’t be possible with individual modalities.
The final stage generates an output based on the processed information. This could be:
Overall, Multi-Modal AI systems bring a powerful blend of data fusion and intelligence processing to unlock new possibilities in various fields like robotics, healthcare, and human-computer interaction.
Let’s take an example to show the implementation process of the Multi-Modal AI System.
The example demonstrates a basic multi-modal model using pre-trained models for image, audio, and text modalities. Here’s a breakdown of each command:
import torch // Core PyTorch library
import torchvision.models as image_models
import torchaudio.models as audio_models
import torchtext.datasets as text_datasets
import torchtext.data as text_data
import torchtext.vocab as text_vocab
# Load pre-trained models
image_model = image_models.resnet152(pretrained=True)
audio_model = audio_models.resnet18(pretrained=True)
text_model = torchtext.datasets.SNLI(root='.data')
# Define the text data pipeline
text_pipeline = text_data.Pipeline(lambda x: x.lower(), lambda x: x.split())
# Build the text vocabulary
text_vocab = text_vocab.build_vocab_from_iterator(map(text_pipeline, text_model))
# Define the multimodal model
class MultiModalModel(torch.nn.Module):
def __init__(self):
super(MultiModalModel, self).__init__()
self.image_model = image_model
self.audio_model = audio_model
self.text_model = text_model
def forward(self, image, audio, text):
image_features = self.image_model(image)
audio_features = self.audio_model(audio)
text_features = self.text_model(text)
return torch.cat([image_features, audio_features, text_features], dim=1)
# Create the multimodal model
multimodal_model = MultiModalModel()
# Define the loss function
loss_function = torch.nn.CrossEntropyLoss()
# Define the optimizer
optimizer = torch.optim.Adam(multimodal_model.parameters(), lr=1e-3)
# Train the model
for epoch in range(10):
for batch in text_model:
image, audio, text = batch
output = multimodal_model(image, audio, text)
loss = loss_function(output, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Evaluate the model
with torch.no_grad():
correct = 0
total = 0
for batch in text_model:
image, audio, text = batch
output = multimodal_model(image, audio, text)
_, predicted = torch.max(output.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy: {100 * correct / total}%')
This code showcases a multimodal AI system that combines image, audio, and text modalities. It utilizes pre-trained models for each modality and fuses their features to make predictions. The model is trained on the SNLI dataset, which consists of image-audio-text triplets and their corresponding labels. The model is evaluated based on its accuracy in predicting the labels.
Multimodal AI, the exciting field where machines process and understand information from multiple senses, like sight, sound, and touch, holds immense potential to revolutionize how we interact with the world. However, its path is paved with challenges that need to be addressed before it reaches its full potential.
Collecting vast amounts of multimodal data is expensive and time-consuming. Annotating a video with synchronized audio and text descriptions, for instance, requires significant human effort.
Multimodal AI models trained on limited or biased data can inherit and amplify those biases, leading to unfair or discriminatory outcomes. Imagine a facial recognition system trained primarily on images of light-skinned individuals, potentially misidentifying people with darker skin tones.
To effectively represent and combine information from different modalities, each with its own characteristics is a complex process. It takes algorithms that can capture subtle relationships between visual and textual data, for example, to merge visual and textual data.
A significant amount of computational resources are required to process and analyze multimodal data. This can limit the scalability and real-world deployment of multimodal AI models.
Multimodal AI models require powerful GPUs and specialized hardware to train on massive datasets. This can limit accessibility and scalability for smaller organizations.
Many multimodal applications, like robotics or augmented reality, require real-time processing of data streams. Developing efficient algorithms and hardware optimized for low latency is crucial for such applications.
Despite these challenges, progress in multimodal AI research is promising. As deep learning architectures, transfer learning, and domain adaptation techniques advance, model performance and generalizability continue to improve. Furthermore, ethical concerns are being addressed through responsible data collection, model development, and deployment practices.
Several industries are going through transformation because of multimodal systems that can comprehend and process information in multiple formats, including text, audio, and images.
Multimodal AI analyzes medical scans, patient records, and even facial expressions to predict disease risk, personalize treatments, and improve diagnosis accuracy. Imagine a system that flags subtle changes in a patient’s voice or facial expressions to alert doctors of potential complications.
The use of multimodal systems personalizes shopping experiences and predicts customer behavior based on purchase history, browsing patterns, and even eye tracking. A virtual assistant could recommend products based on your gaze and past purchases, making shopping easier and more enjoyable.
A multimodal system analyzes sensor data, images, and sounds from machines to predict equipment failure, improve production lines, and increase quality control. Consider a system that alerts users if a machine begins to vibrate before it fails, which would prevent costly downtime.
By integrating GPS, traffic data, and even weather information, multimodal systems optimize routes for delivery trucks and autonomous vehicles. Imagine a self-driving car that adjusts its speed based on not just road signs, but also real-time weather updates and pedestrian movements.
Multimodal systems analyze student interactions, facial expressions, and even eye movements to personalize learning experiences and identify struggling students. Imagine a virtual tutor that adapts its teaching style based on your body language and comprehension level, ensuring education caters to individual needs.
Unimodal AI and Multimodal AI are two distinct approaches to artificial intelligence, each with its own characteristics and applications. Here are the key differences between the two:
| Feature | Unimodal AI | Multimodal AI |
|---|---|---|
| Data source | Single modality (text, image, audio, etc.) | Multiple modalities |
| Processing | Focused on extracting insights from one data source | Connects information from multiple modalities |
| Algorithms | Trained on specific data types | Complex algorithms for multimodal fusion |
| Applications | Tasks like image recognition, text analysis, speech recognition | Tasks requiring a richer understanding of data, like sentiment analysis, object detection in videos, human-computer interaction |
| Advantages | Simpler to implement, computationally less expensive | More accurate and robust results, a better understanding of complex data |
| Disadvantages | Limited in scope, may miss important information | Complex to implement, computationally expensive |
Ultimately, the choice between unimodal and multimodal AI depends on the specific task and data at hand. Unimodal AI remains valuable for simpler tasks with consistent data, while multimodal AI shines in complex situations requiring a deeper understanding of the real world.
Generative AI and Multimodal AI are two different approaches to artificial intelligence that serve different purposes.
| Feature | Generative AI | Multimodal AI |
|---|---|---|
| Focus | Single modality (e.g., text, image) | Multiple modalities (e.g., text + image + audio) |
| Strengths | Highly creative outputs, originality | A deep understanding of complex relationships |
| Goal | Generate new content | Understand and process data from different sources |
| Weaknesses | Limited to single data type, factual accuracy, bias | Requires large amounts of diverse data to train effectively |
| Models | Use Deep learning techniques such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) to generate new data. | Use deep learning techniques such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) to process and analyze data from multiple modalities. |
| Examples | LLMs, text-to-image models, generative music models | Sentiment analysis, medical diagnosis systems, and robots with multimodal navigation |
It’s important to note that Generative AI and Multimodal AI are not mutually exclusive. In fact, the future of AI likely lies in the convergence of these two fields, where models can both generate new content and understand the world through multiple modalities. This combination could lead to even more powerful and versatile AI applications.
Multi-modal AI systems, capable of processing and understanding information from multiple senses like sight, sound, and touch, are poised to revolutionize the way we interact with technology and experience the world.
The future of multi-modal AI is brimming with possibilities. These systems have the potential to revolutionize various industries, enhance human-computer interaction, and even improve the quality of our lives. In order to realize the full potential of this technology, it will be necessary to navigate the challenges and ensure ethical development.
The potential of multimodal AI is truly remarkable, transforming not only how we interact with technology but also how industries operate. By seamlessly integrating different types of data, it opens up a world of possibilities that were once thought to be in the realm of science fiction. The exciting part is that we have only scratched the surface of what multimodal AI can do. Imagine a future where your car understands your emotions, your doctor can diagnose your health condition with the help of AI, or you can have a personalized shopping experience – all thanks to multimodal AI!
If you’re interested in integrating this groundbreaking technology into your business processes, our team of experts at CodeTrade is ready to help. Let’s explore the future together!
 Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash