
AI
 Chand Prakash
10 July 2026
Chand Prakash
10 July 2026
From PoC to Production: A 90-Day AI Deployment Playbook for Enterprise
 Chand Prakash
Chand Prakash
Self-organizing maps (SOMs), also known as Kohonen maps, are a type of artificial neural network used for unsupervised learning tasks such as cluster neural networks used for unsupervised learning tasks such as clutter and reduced dimensionality. SOMs train using a competitive learning algorithm, in which neurons compete to represent the input data. This results in a two-dimensional grid of neurons, where similar data points map to nearby neurons.
This blog post introduces self-organizing maps (SOMs) and their applications, including fraud detection. Also provides a step-by-step guide to implementing SOMs for fraud detection.
Imagine you have a map, and you want to organize data points on it in a way that captures their inherent structure and relationships. This is precisely what a Self-Organizing Map (SOM) does in the world of machine learning. SOM was developed by Teuvo Kohonen in the 1980s.
At its core, SOM consists of an array of neurons arranged in a grid-like fashion. Each neuron has an associated weight vector that represents a point in the data space. During training, SOM learns to adapt these weight vectors to the input data in a way that nearby neurons on the map respond to similar input patterns. This self-organization process is what makes SOM so powerful.
SOM architecture works based on a two-dimensional grid of neurons. Each neuron in the grid has a weight vector that initializes randomly. The weight vector represents the position of the neuron in the input space.
Over time SOM neurons learn to represent different features of the input data, which organizes the data into a two-dimensional map.
Also Read: How to Use Linear Regression to Make Predictions in Machine Learning
SOMs have a wide range of applications in machine learning, including:
SOMs can be used to implement a fraud detection system by following these steps:
Preprocess the data to ensure that it is in a format that is compatible with the SOM algorithm. To process the data you have to execute the given steps:
To execute data processing we have to implement 3 libraries,
# import the libraries import numpy as np import pandas as pd import matplotlib.pyplot as plt
To import the dataset we use Pandas library to load the Credit Card Application dataset from Kaggle into a DataFrame. then split the dataset into independent and dependent variables using the iloc function, which we store in the variables X and y, respectively.
# import the database from kaggle
dataset = pd.read_csv('Credit_Card_Applications.csv')
#independent variables
X = dataset.iloc[:, :-1].values
# dependent variables
y = dataset.iloc[:, -1].values
It is important in data preprocessing because it helps to normalize the features so that they have the same scale. This makes it easier for machine learning algorithms to learn from the data. The MinMaxScaler class from the scikit-learn library is a popular normalization technique that scales the features so that they fall within the range [0, 1].
from sklearn.preprocessing import MinMaxScaler sc = MinMaxScaler(feature_range = (0,1)) X = sc.fit_transform(X)
Train a SOM on the preprocessed data.
If you use the MiniSom model for SOMs and you get an error, you need to install it using the following command:
#!pip install minisom from minisom import MiniSom
To initialize a SOM model, we need to specify a few parameters:
som = MiniSom(x=10,y=10,input_len=15, sigma=1.0,learning_rate=0.5)
We randomly initialize the weights of our SOM model using our data (X).
som.random_weights_init(X)
In this step, we train the SOM model. We pass two parameters to the training function: the input data and the number of iterations. In this example, we choose 100 iterations.
som.train_random(data = X, num_iteration = 100)
To simply visualize a self-organizing map(SOM) use the following code:
# Imports the necessary libraries from pylab
from pylab import bone, pcolor, colorbar, plot, show
#Creates a bone colormap.
bone()
#Creates a pcolor plot of the SOM's distance map
pcolor(som.distance_map().T)
#Adds a colorbar to the plot
colorbar()
#Defines the marker types and colors that will be used to plot the data points
markers = ['o','s']
colors = ['r','g']
#Iterates over the input data
for i,x in enumerate(X):
#Finds the winning node for the current data point
w = som.winner(x)
#Plots a marker at the winning node for the current data point
plot(w[0] + 0.5,
w[1] + 0.5,
markers[y[i]],
markeredgecolor = colors[y[i]],
markerfacecolor = 'None',
markersize=10,
markeredgewidth=2)
#Displays the plot
show()
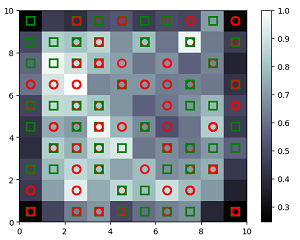
The Self-Organizing Map (SOM) visualizes customer data, where red circles represent customers who did not get approval and green squares represent customers who did get approval. Outliers, shown in white, have a high potential for fraud.
To catch the potential fraud, we need to map the winning code using the given code.
# mapping the winning node mappings = som.win_map(X)
The code creates a dictionary that maps each winning node to its customers. This dictionary can be used to identify potential fraud by looking for customers that are mapped to winning nodes with high inter-neuron distances (IND). IND is a measure of how different a winning node is from its neighbors. Outlier data points, such as fraudulent customers, are more likely to have higher INDs.
Use the given Python code to catch the cheater using SOM.
frauds=np.concatenate((mappings[(7,8)], mappings[(3,1)], mappings[(5,1)]), axis=0)
The code first uses a self-organizing map (SOM) to map the winning node for each customer. The winning node is the node on the SOM that is most similar to the customer’s data. The code then takes only the customers whose winning nodes are [(7,8), (3,1), and (5,1)]. These customers are flagged as potential fraud customers because their winning nodes are outliers on the SOM.
# Rescale the values of the potential fraud customers
for i in range(len(frauds)):
frauds[i] = inverse_scale_function(frauds[i])
This code will rescale the values of the potential fraud customers back to the original scale using the inverse scale function. The inverse scale function scales the values before training the SOM.
# Print the list of potential fraud customers in the original scale print(frauds)
The final result of catching fraud using SOM is a list of customers who are most likely to be cheating. The generated list by SOM helps to identify customers whose winning nodes are outliners. The winning node for a customer is the node on the SOM that is most similar to the customer’s data.
The guide will help you to find fraud detections using SOMs. Also, Self-Organizing Maps (SOMs) are a powerful type of unsupervised machine-learning algorithm that helps to reduce dimensionality, visualize data, and cluster data points. It is particularly useful for analyzing high-dimensional data, as it can project the data into a lower-dimensional space while preserving the underlying relationships between the data points.
If you are working with high-dimensional data or if you need to develop a machine learning algorithm that can learn without labeled data, then SOMs are a good option to consider.
Get a free consultation for AI & ML from CodeTrade, a leading AI & ML Development Company in India. We offer a free consultation to help you understand how to use AI and ML to improve your business. Our team of experienced AI and ML developers can provide you with high-quality AI and ML services tailored to your specific needs.
 Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash