
Generative AI Consulting Services: From Idea Validation to Deployment Strategy
 Chand Prakash
Chand Prakash

Object detection has become an integral part of computer vision applications that enable machines to not only recognize but also localize and classify objects within images. YOLO (You Only Look Once) has emerged as a powerful and efficient algorithm for object detection, and with the release of YOLOv7, developers now have a robust tool to perform custom object detection tailored to their specific needs. In this developer’s guide, we will delve into the process of implementing custom object detection with YOLOv7.
YOLOv7 is an open-source object detection algorithm developed by Alexey Bochkovskiy and the Ultralytics team. It is a single-stage detection algorithm, which means it predicts bounding boxes and class probabilities for objects in an image in a single step. This makes YOLOv7 very fast which makes it suitable for real-time applications. Before diving into the customization process let’s understand the basics of YOLO7:
YOLOv7, the latest version of this object detection algorithm, represents a significant leap forward in object detection technology. It boasts several enhancements that improve its accuracy, speed, and versatility:
YOLOv7 is a state-of-the-art object detection algorithm that belongs to the You Only Look Once (YOLO) family of models. It is known for its remarkable accuracy and speed, making it a popular choice for real-time object detection applications. The YOLOv7 architecture consists of three main components:
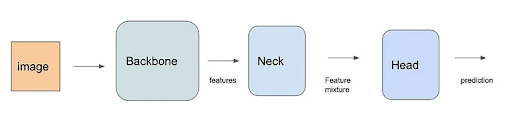
The backbone is responsible for extracting high-level features from the input image. It is typically composed of a series of convolutional layers that gradually reduce the spatial dimensions of the feature maps while increasing the number of channels. YOLOv7 employs the Cross-Stage Partial connections (CSPDarknet53) backbone, which is a modified version of the Darknet53 backbone used in previous YOLO models.
The neck is responsible for combining and fusing the feature maps from different stages of the backbone. It aims to extract multi-scale features that are suitable for object detection at different scales. YOLOv7 utilizes the Path Aggregation Network (PANet) neck, which consists of a feature pyramid network (FPN) that combines feature maps from different backbone stages and a path aggregation module that further enhances feature fusion.
The head is responsible for generating the final object detection predictions. It takes the feature maps from the neck and predicts the bounding boxes and class probabilities for each object. YOLOv7 employs a multi-scale prediction head that utilizes three different anchor boxes to handle objects of varying sizes.
Specifically, YOLOv7 architecture looks like:
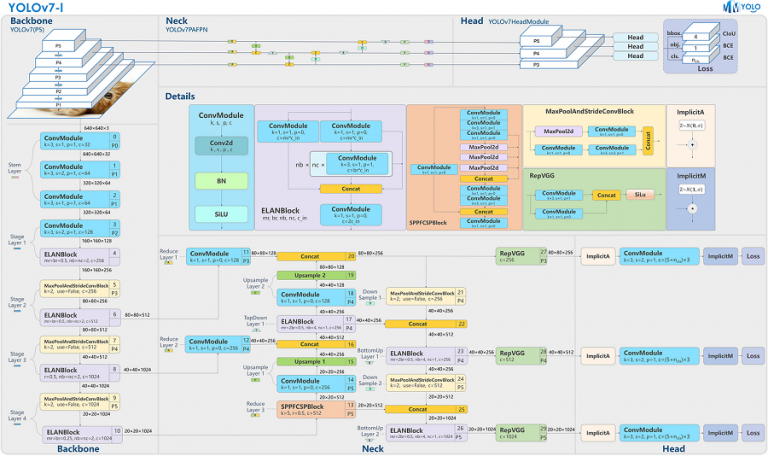
YOLOv7 introduces several novel architectural improvements that contribute to its superior performance:
E-ELAN is a novel computational block that enhances feature extraction and information flow within the backbone. It utilizes a combination of expand, shuffle, and merge operations to improve the model’s learning ability without destroying gradient paths.
YOLOv7 employs a multi-scale prediction head with auxiliary losses at intermediate stages. The auxiliary losses are trained on coarse predictions, while the lead loss focuses on fine-grained predictions. This strategy helps to stabilize training and improve overall accuracy.
YOLOv7 utilizes a label assigner mechanism that assigns soft labels to the network predictions based on the ground truth annotations. This mechanism helps to improve the model’s ability to handle overlapping instances and partial occlusions.
YOLOv7 incorporates several additional techniques, including the Mish activation function, weighted-SiLU activation function, and cosine similarity for anchor matching, which contribute to its overall performance gains.
Overall, YOLOv7 is a state-of-the-art object detection algorithm that is known for its speed, accuracy, and efficiency.
Implementing YOLOv7 for custom object detection involves several steps. YOLOv7 is an improved version of the YOLO (You Only Look Once) object detection algorithm. Here are the general steps to implement YOLOv7 for custom object detection:
Clone the YOLOv7 repository from GitHub. The official repository can be found at https://github.com/WongKinYiu/yolov7. Use the following command to clone the repository:
git clone https://github.com/WongKinYiu/yolov7.git
Navigate to the YOLOv7 directory and install the required dependencies. The required dependencies are listed in the requirements.txt file. You can install them using:
pip install -U -r requirements.txt
Organize your custom dataset in YOLO format. Each annotation file should contain information about the bounding box and class label for each object in the image. Separate the dataset into training and validation sets.
1. Modify the YOLOv7 configuration files to suit your custom dataset and training requirements. Configuration files are located in the ‘yolov7/data directory’.
2. Edit ‘data/custom.yaml’ with the paths to your custom dataset, number of classes, and other dataset-specific settings.
3. Adjust hyperparameters in ‘yolov7/models/yolov7-custom.yaml’ based on your preferences and hardware capabilities.
Download pre-trained weights for YOLOv7:
wget https://github.com/WongKinYiu/yolov7/releases/download/v1.0/yolov7.pt
Start the training process using the custom dataset and configuration:
python train.py --img-size 640 --batch-size 16 --epochs 30 --data data/custom.yaml --cfg models/yolov7-custom.yaml --weights yolov7.pt
Adjust the parameters such as ‘img-size’, ‘batch-size’, and ‘epochs’ according to your requirements.
After training, evaluate the model on the validation set to assess its performance:
python test.py --img-size 640 --conf-thres 0.001 --iou-thres 0.6 --data data/custom.yaml --cfg models/yolov7-custom.yaml --weights runs/train/exp/weights/best.pt
Replace the path to the weights file with the one generated during training.
Apply the trained model to conduct object detection on fresh images or videos.
python detect.py --img-size 640 --conf-thres 0.3 --source path/to/test/images --weights runs/train/exp/weights/best.pt
Adjust the conf-thres parameter based on the desired confidence threshold.
If the model’s performance is unsatisfactory, consider fine-tuning hyperparameters or augmenting the dataset to further improve accuracy.
Deploy the trained model in your desired application or platform for real-world use.
Make sure to refer to the official YOLOv7 documentation and GitHub repository for any updates or changes in the implementation process. Additionally, be mindful of licensing and usage terms associated with the YOLOv7 code and pre-trained weights.
With these simple implementation steps, you can easily implement YOLO7 for the Custom Object Detection model.
Custom object detection with YOLOv7 opens up a world of possibilities for developers looking for accurate and efficient solutions. By following this guide, you’ve taken a significant step toward mastering YOLOv7 for your specific use case. Experiment with different parameters, datasets, and training strategies to optimize the model for your unique requirements.
If you are looking for expert AI ML developers, Hire dedicated and talented AI ML developers from CodeTrade, a leading AI ML development company based in India. Our team of highly skilled and experienced developers possesses the expertise to tackle your most complex AI/ML challenges. Empower your business with AI/ML. Contact CodeTrade today!
 Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash Chand Prakash
Chand Prakash